
Near-Real-Time Speaker Diarization on CoreML
Lessons learned converting PyTorch models to run locally at zero marginal cost on Apple's Neural Engine
Voice-based AI apps are gaining significant popularity as whisper models have democratized speech-to-text, but transcription alone isn't enough. Voice AI apps need to know who said what and when. That's where speaker diarization solves this issue by detecting and labeling different speakers in real time, bringing essential structure and clarity to transcripts. In a meeting with many participants, you need to attribute action items and follow-ups to the right person.
Many existing diarization systems rely on cloud processing, but that introduces major cost and latency issues. Streaming audio buffers to the cloud introduces unpredictable delays, especially over cellular networks. Additionally, every minute of cloud inference incurs variable costs from AI compute time to bandwidth, latency round trips, and storage; this makes cloud-based diarization expensive at scale. For example, Picovoice's proprietary diarization costs up to $3 per hour of audio, making processing 1,000 hours of meetings cost up to $3,000.
While post-processed diarization can be more accurate, it introduces its own problems. One major issue is cold start: when users launch a voice app, post-processing systems initially assign generic labels like "Speaker 1" and "Speaker 2." These labels lack real-world context, forcing users to guess who said what after the fact. This adds cognitive friction and undermines the value of automation. In contrast, real-time diarization allows assigning names or roles as people begin speaking, maintaining consistent speaker identity throughout both intra-session and inter-session periods.
This article will go into detail on our attempt and learnings from trying to convert diarization models to run efficiently on CoreML, and how the Fluid Inference platform helped us achieve this in a fraction of the time it would have taken otherwise.
The Limitations of Current Local Diarization Solutions
There are some solutions out there that allow developers to run speaker diarization models on local devices like macOS, but they were either focused on CPU, written in Python, or had proprietary licensing. As developers building local AI applications across Apple, Windows, and Android, we've experienced firsthand how limiting these constraints can be.
Pyannote, while widely regarded as a benchmark for speaker diarization, does present notable limitations for on-device, real-time applications. Its Python-based implementation is ill-suited for native macOS development. Adding Python as a dependency introduces a substantial download size, requiring approximately 200MB for a minimal Python installation plus 350-500MB for the necessary computing libraries (NumPy, PyTorch, and SciPy). This is unsuitable for native applications that are usually less than 100MB in total.
Another option was sherpa-onnx, which offered Swift support; however, it falls short for real-time, on-device diarization on macOS due to its lack of support for ANE (Apple Neural Engine), requiring inferencing on the CPU. This resulted in higher latency and power usage—critical drawbacks for real-time applications. Additionally, sherpa-onnx lacks tight integration with Swift and CoreML, making it cumbersome to manage for macOS development with all the C++ header files and bindings. These limitations ultimately led us to favor a CoreML pipeline optimized for Swift processing and Apple hardware.
Engineering On-Device Diarization
Converting PyTorch Models to CoreML
There were other speaker diarization models that we were considering for conversion but we ultimately went with Pyannote’s segmentation model and WeSpeaker embedding because of their popularity, accuracy and speed.
Speaker diarization uses two models; the segmentation and speaker embedding model. Running these models efficiently on macOS and iOS required integration with Apple's on-device machine learning ecosystem. At the core of this is CoreML, Apple's framework for executing machine learning models directly on devices, which presented unique challenges and required careful engineering.
The first major issue we encountered for model conversion was that the PyTorch library had functions that were unsupported in CoreML files. For example, when attempting to convert the embedding model, we encountered runtime errors such as:
# Original PyTorch code using unsupported operations
features = torch.vmap(fbank_partial)(waveforms) # vmap not supported in CoreML
# Replaced with this
features = torch.stack([fbank_partial(w) for w in waveforms.to(fft_device)]).to(device)# Original code that caused: "RuntimeError: PyTorch convert function for op 'as_strided' not implemented"
return waveform.as_strided(sizes, strides)
# Our implementation using basic operations supported by CoreML
frames = []
for i in range(0, waveform.size(0) - window_size + 1, window_shift):
frames.append(waveform[i:i + window_size].unsqueeze(0))
frames = torch.cat(frames, dim=0)Furthermore, the fbank computation, a critical precursor to many audio models, had to be re-implemented outside the converted model to ensure full compatibility. These adaptations required extensive knowledge of both PyTorch internals and CoreML capabilities, making the conversion process labor-intensive and error-prone.
Another issue is dynamic graph versus static graph support; CoreML currently only supports static graph usage. This was encountered during our embedding model conversion process. During tracing, we discovered that Pyannote's internal logic contained conditional statements dependent on input audio dimensions. This led to a dynamic graph that torch.jit.trace couldn't resolve into a static representation. Our workaround involved modifying the code to handle only 1D audio inputs, effectively removing the problematic conditional paths and allowing for successful graph tracing.
Building a Real-Time Processing Pipeline
We needed a system that could make accurate speaker assignments on the fly. However, during our research, we found most speaker diarization algorithms were designed for post-processing. This meant we needed to rethink traditional pipelines and get creative with optimization strategies to balance accuracy and the constraints of real-time, on-device inferencing.
While apps like Zoom or Slack Huddles appear to offer real-time speaker identification, it's important to note that they operate within their own ecosystems. These platforms own the audio routing, so they know exactly which user is speaking at any given time based on internal metadata—not from analyzing the audio itself. In contrast, our diarization system works on raw, single-channel audio with no privileged access to speaker identity, making the problem of local model device support difficult.
The original Pyannote models were designed to operate on 10-second chunks using a sliding window approach to detect speaker segments from full audio files. Additionally, the speaker embeddings tend to degrade in accuracy when generated from less than 3 seconds of speech. However, during testing, this 10-second chunk design did not negatively impact the perceived real-time responsiveness of the system. Since the diarization is designed to run locally on the user's machine, using longer chunks also allows for smoother computation without compromising interactivity.
For every 10-second audio chunk, here's how our pipeline operates:
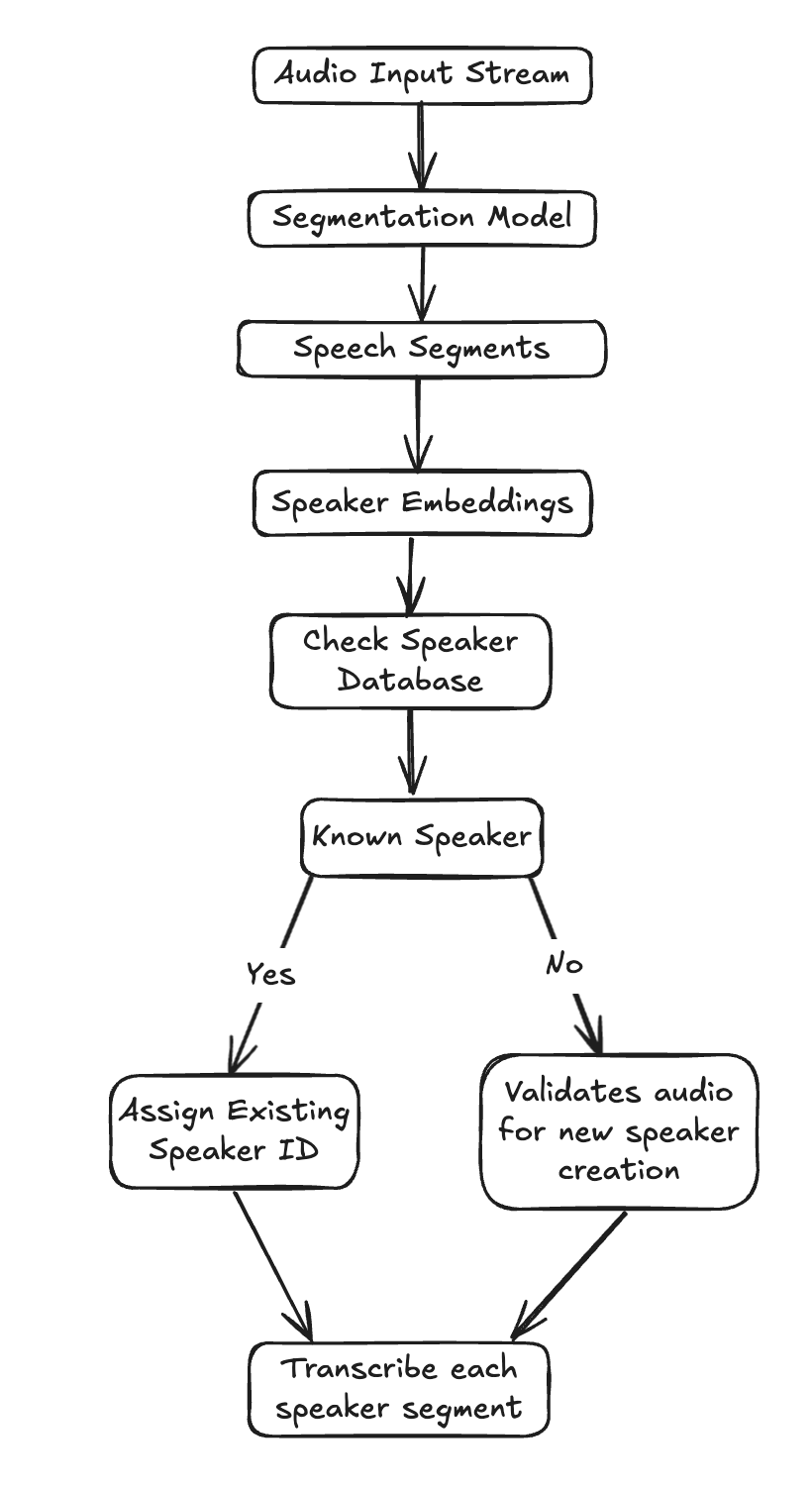
Speech Segmentation: We first feed the audio chunk into our Segmentation model, identifying precise time intervals within that 10-second window where speech activity occurs, effectively telling us when someone was speaking.
Speaker Embedding Generation: Next, for each of these detected speech segments, we generate a speaker embedding. Think of this as a digital fingerprint for the speaker's voice during that specific segment—a compact numerical representation capturing their vocal characteristics.
Speaker Assignment: Finally, we take this newly generated speaker embedding and compare it against our existing registry of known speakers. We then assign the segment to the closest matching speaker, ensuring consistent identification even as the conversation progresses.
This iterative process allows us to continuously update speaker information as audio comes in, providing dynamic diarization that keeps pace with the conversation. While it does come at the tradeoff of some accuracy, it is sufficient for our real-time diarization utility.
Managing Voice Clustering in Real-Time
Our diarization system begins with a clean slate: an empty speaker registry. As our pipeline generates new speaker embeddings from incoming audio segments, we perform an immediate check against this existing list. If no sufficiently close match is found for a new embedding, we consider it a potential new speaker.
During our development, we encountered spurious speaker entries (e.g., from brief coughs, background noise, or short interjections), so we implemented a crucial filter: a new speaker embedding is only officially added to our database if that voice has been detected speaking for a cumulative duration exceeding three seconds, along with some basic speech-to-noise ratio algorithms to detect non-speech noises. These procedures helped ensure the robustness of our speaker identification.
Furthermore, human voices are not static; they can exhibit subtle acoustic drift over time due to factors like microphone changes, emotional state, or even just long conversations. To accommodate this, we continuously update our existing speaker embeddings using exponential smoothing. This technique allows the model to adapt to subtle changes in a speaker's voice over the course of a meeting, ensuring long-term accuracy without creating new, redundant speaker identities.
Speed vs. Accuracy Performance Trade-offs
Our diarization models achieved an average DER of 22.14% across standard benchmarks (excluding the AVA-AVD dataset), compared to the open-source Pyannote 3.0's 17.0%. While we trail by about 5% in accuracy on most datasets, FluidAudio speaker diarization was designed for real-time performance, and degradation was expected, whereas Pyannote was designed primarily for post-batch processing. Interestingly, we significantly outperform on the AVA-AVD dataset (32.6% vs. 49.1%), though this is largely due to our different handling of silent frames and non-speech audio, as well as different threshold tuning for some of the datasets on our end.
Quantization and Optimizations
Once we were able to get the models in a working state, we naturally started exploring further optimizations to reduce the speed and size of the models. Interestingly, coming from an LLM world where quantization usually leads to faster performance with sacrifice to accuracy, the assumption did not exactly translate for CoreML models. This is one area we have been able to automate completely, relying on our AI Agent to generate a comparison against the baseline model. This graph was generated with a single natural language prompt; working together with several other sub-agents, it was able to output this for a human to review, saving days of manual work for an ML engineer.
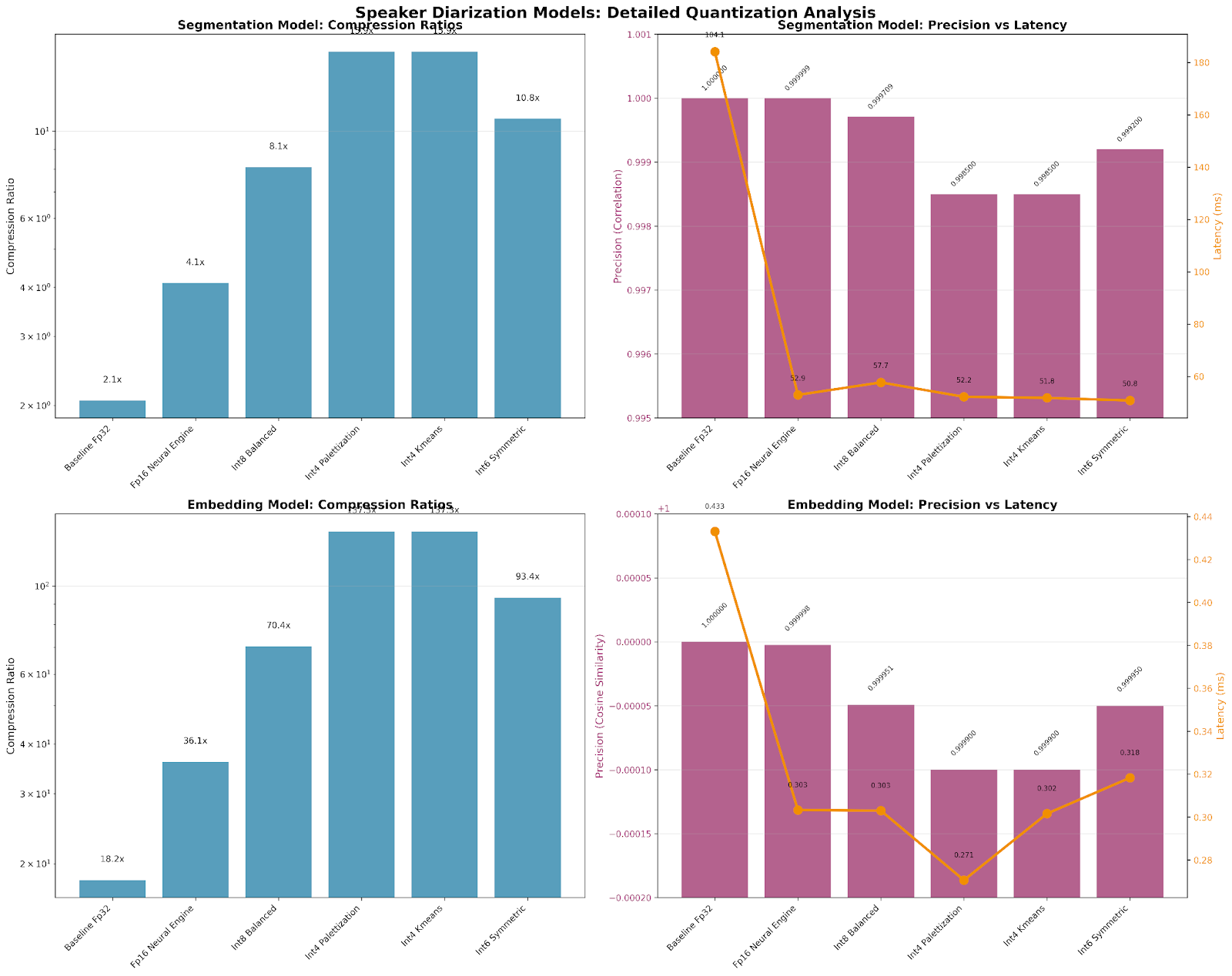
The final recommendation was to keep the baseline fp32 models. Even though a quantized model showed significant compression, the size reduction and latency gains were not significant enough for the precision tradeoff for both models.
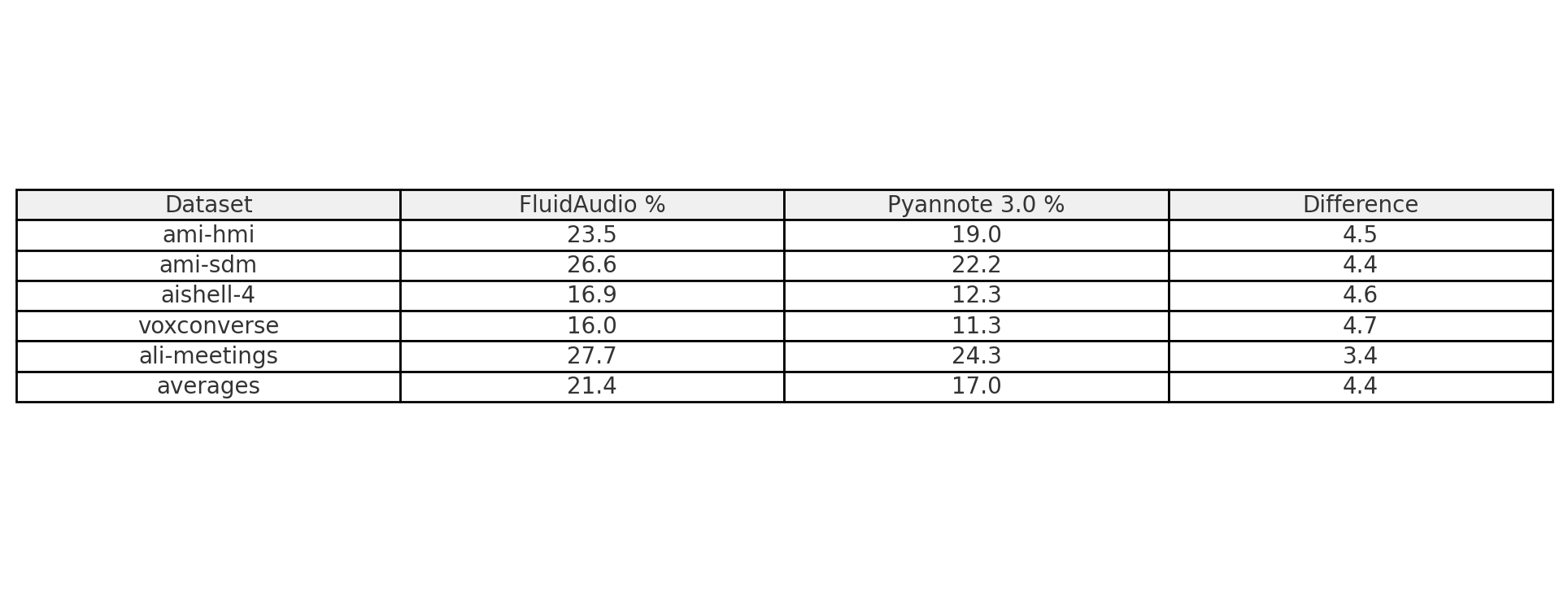
FluidAudio achieved 0.017 RTF (60x real-time) on a 2022 Apple M1, outperforming Pyannote's 0.025 RTF (40x real-time) on an enterprise-grade Nvidia Tesla V100. This 50% speed advantage on far more accessible hardware is made possible by CoreML optimizations, leveraging ANE through native Swift integration. It's also worth noting that Pyannote performs post-processing clustering across all embeddings, an inherently computationally expensive step that contributed to its slower performance.
We launched this publicly a month ago, and since then, we have seen overwhelming interest. The project quickly grew to over 400 stars in a month, with thousands of models downloaded on Hugging Face and multiple production AI applications rolling it out in their apps.apps.
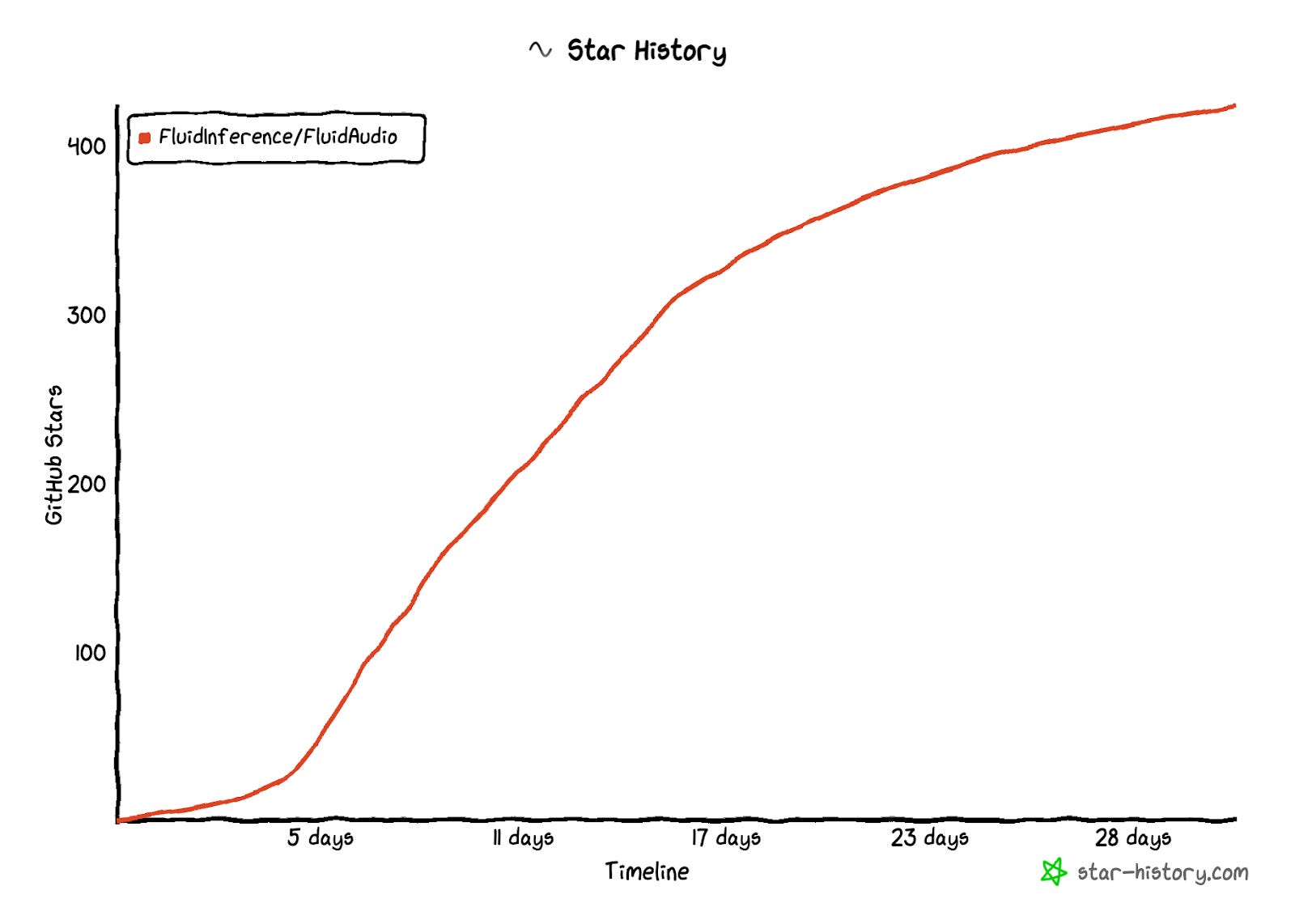
From Open Source to Enterprise Success
We decided to tackle this challenging problem of enabling local real-time speaker diarization because we believe in the long-term success of local model development, despite the mounting challenges we encountered while trying to get it running locally. With cloud computing, the latency issues would render real-time applications inapplicable or unusable, especially given the computational intensity of AI.
Our knowledge investment has significantly paid off. Through our experience with the speaker diarization conversion, we're excited to share that our Parakeet model is already available for testing in the same repository. Several production macOS and iOS applications have already integrated FluidAudio for speaker diarization, like slipbox.ai, whisper.marksdo.com, and Beingpax/VoiceInk.
We've even expanded beyond Apple platforms, with our models now running on Windows NPU as well, and we're working with Fortune 100 companies to deploy custom models on their AI accelerators.
If you're interested in implementing on-device speaker diarization in your applications or would like to explore collaboration opportunities, join our Discord or drop us an email at hello@fluidinference.com.
Hi, great project, first of all. I've started using FluidAudio in my side project through writing a custom Expo module. Local computing is usually ignored despite the power of modern mobile devices.
The form link at the end of the post seems broken, I'd like to contribute to the project.
Cheers