
Teaching AI to Optimize AI Models for Edge Deployment
How our agent, Möbius automated a Core ML port in ~12 h (vs. 2 weeks), hit 0.99998 parity, and made it 3.5× faster, while staying on the CPU.
TLDR: We’re building Möbius, an AI agent for model porting. In early tests, it helped convert Silero VAD from PyTorch to Core ML in 12 hours with human guidance, achieving 0.99998 accuracy parity and 3.5× CPU speedup. We’re extending this approach to OpenVINO, TensorRT, and other edge runtimes.
Why Voice-Activity-Detection matters for edge AI
Voice activity detection (VAD) answers a simple question many times per second: did this audio slice contain speech? Because VADs rely on acoustics, they’re language-agnostic and typically under 5MB, making them perfect for local, always-on use. They sit in front of automatic speech recognition (ASR), text-to-speech (TTS), and voice agent systems, improving quality and keeping latency predictable.
In this article, we show how we’re building Möbius, our AI agent platform to help developers bring modern AI models onto edge devices. Like Codex or Claude Code for general programming, Möbius will work with a human. In this early test, we used our prototype to help convert Silero VAD, one of the most popular VAD models, from PyTorch to Apple’s native Core ML runtime. While this example converts PyTorch to Core ML, we’re designing the approach to generalize to other runtimes like OpenVINO and TensorRT.
Our manual conversion failed after two weeks
Our team has ported several models, including FluidInference/parakeet-tdt-0.6b-v3-coreml and Pyannote models for speaker diarization. We previously converted Silero VAD v5 manually. A team member without prior experience, mentored by a researcher with over 20 years in ML, spent about two weeks on it. The result was broken with ±0.15 to 0.2 probability drift, no speed improvements, and inconsistent behavior.
This time, we tested our Möbius prototype on v6 from scratch, with only select context from data we’ve collected. Our goal wasn’t just another porting example but to demonstrate that given the right context and knowledge, an AI agent can search, reason, verify, and help optimize, turning a months-long process into hours while discovering optimizations most humans miss. Just as Vercel abstracted infrastructure for web apps, we want developers to bring models to edge applications just as easily.
Why are we building Möbius?

Our team’s background is in traditional ML and distributed systems, building recommendation systems and content moderation serving over a billion users. We’ve spent years scaling cloud infrastructure across AWS, Azure, and GCP. Edge systems are relatively new territory for us, but we’ve found that many concepts from distributed systems translate surprisingly well to edge optimization.
After tinkering with edge AI applications and deploying it to users, we quickly realized the hardware is catching up but the software layer is really behind and isn’t improving fast enough. Running near-realtime workloads on consumer CPUs and GPUs was too slow and drained battery life for most consumer hardware. Interestingly, enterprises and healthcare providers started reaching out, asking how they could run modern models locally for privacy and compliance reasons.
While some solutions exist for running local AI models on edge devices, most are only partially open or integrate poorly with native applications. We found this frustrating when building our own solution, so instead of waiting for others to solve the problem, we decided to tackle it ourselves and share our models and SDKs with everyone.
The fragmented ecosystem is evolving quickly and new models are being released with different architectures. Instead of the traditional static compiler approach, we wanted to tackle this differently using AI itself to solve the problem. That’s why we’re building Möbius as an AI agent that captures these optimization patterns, making edge AI accessible to everyone, not just hardware or machine learning engineers. By bridging this gap, Möbius lets teams leverage their existing distributed systems expertise while navigating the unique constraints of on-device inference.Retry
Core ML is more than Apple’s Neural Engine
Before diving into how möbius solved this, it’s important to understand what Core ML really is. While it’s the only developer interface to Apple’s Neural Engine (ANE), Core ML is Apple’s complete on-device machine learning runtime framework that can target CPU, GPU, and ANE.
Core ML uses heuristics, operator support tables, and runtime constraints to decide where each part of your model runs. You get control through the model configuration’s computeUnits setting, allowing you to limit or prefer certain compute units, though it’s not guaranteed.
What makes Core ML powerful isn’t just hardware access but its deep ecosystem integration. Ahead-of-time compilation means models compile before runtime, helping with startup latency and enabling graph-level optimizations. The unified memory architecture lets CPU, GPU, and ANE share the same memory pool, eliminating data copying between compute units.
For CPU execution, Core ML leverages Accelerate and Basic Neural Network Subroutines (BNNS) for many operations and potentially fuses operations. It also supports weight palettization as a compression technique, as well as more traditional quantization depending on the OS version and target. Automatic compute unit selection dispatches operations to the best unit based on support and cost.


As with any abstraction, there are trade-offs. Apple doesn’t expose all internal decision logic, and there are strict requirements for input/output dimensions, internal state, and static data structures. Not all operations convert the same, and you often have to remap operations to Core ML’s supported set.
Model conversion requires translation, not just export
Running a model in another runtime is like rewriting code in a different programming language. You’re taking the same logic and structure but lowering one operator graph into the target runtime’s supported operations without changing the math or state semantics.
This brings familiar challenges. Not all operators have direct equivalents. Most AI accelerators work best with static graphs with fixed dimension inputs. You run into control flow gaps where some operations lack direct equivalents. There’s the challenge of dynamic versus static execution since most accelerators require static graphs. And tracing limitations mean not all operations export cleanly.
We often run into dimension limitations, dynamic graphs, state, and operations not being supported. Despite these hurdles, porting to a native runtime is worth it. You gain access to vendor-tuned optimizations, and performance can be significantly better, sometimes even when the final model executes on CPU only, thanks to ahead-of-time graph compilation and optimized memory layouts.
Theoretically someone could craft custom kernels that might outperform Core ML models, but those are extremely rare cases. On Apple devices, you lose access to Apple’s internal optimizations that are often opaque and restricted without using Core ML.
Building Möbius to help bring AI to the edge
Rather than building new models or writing kernels from scratch, we’re developing Möbius as a specialized AI agent to assist developers with model conversion. Like other coding agents, it’s designed to work alongside engineers, handling the repetitive and complex parts while humans provide guidance and verification. We’re creating an orchestration layer that combines frontier LLMs like Claude with domain-specific tooling and continuous learning capabilities through memory and models we’re training specifically for runtime optimization.
Each conversion teaches our system new patterns. We deliberately target true positives, collecting examples where the agent gets blocked and their solutions. We’ve found this better skews outputs toward positive outcomes than providing true negatives, which lead the agent down incorrect paths more frequently.
While our roadmap leads toward more autonomy, our current prototype operates as an AI coding partner that can dramatically reduce the time needed to bring an AI model to an edge device. A developer still drives the process, but instead of spending weeks debugging numerical differences and rewriting operations, they can guide our agent through the conversion in hours. In essence, we’re democratizing access to expert-level model optimization, enabling any developer to achieve what previously required specialized ML engineering expertise.
Mapping models and breaking apart black boxes
Our prototype begins by understanding what it’s working with, gathering requirements from the user and clarifying the model’s use case. Typically, users need to provide access to the existing model as well as details about the desired platform and programming language for running the inference model.
To start our test, our team member provided a link to the Silero VAD GitHub repository and confirmation that the model would run on macOS 13+ and iOS 15+ as a prompt. If we increase the minimum OS version, we might get more optimizations, but users often lag behind in upgrades, so we prefer to support a wider number of users first.
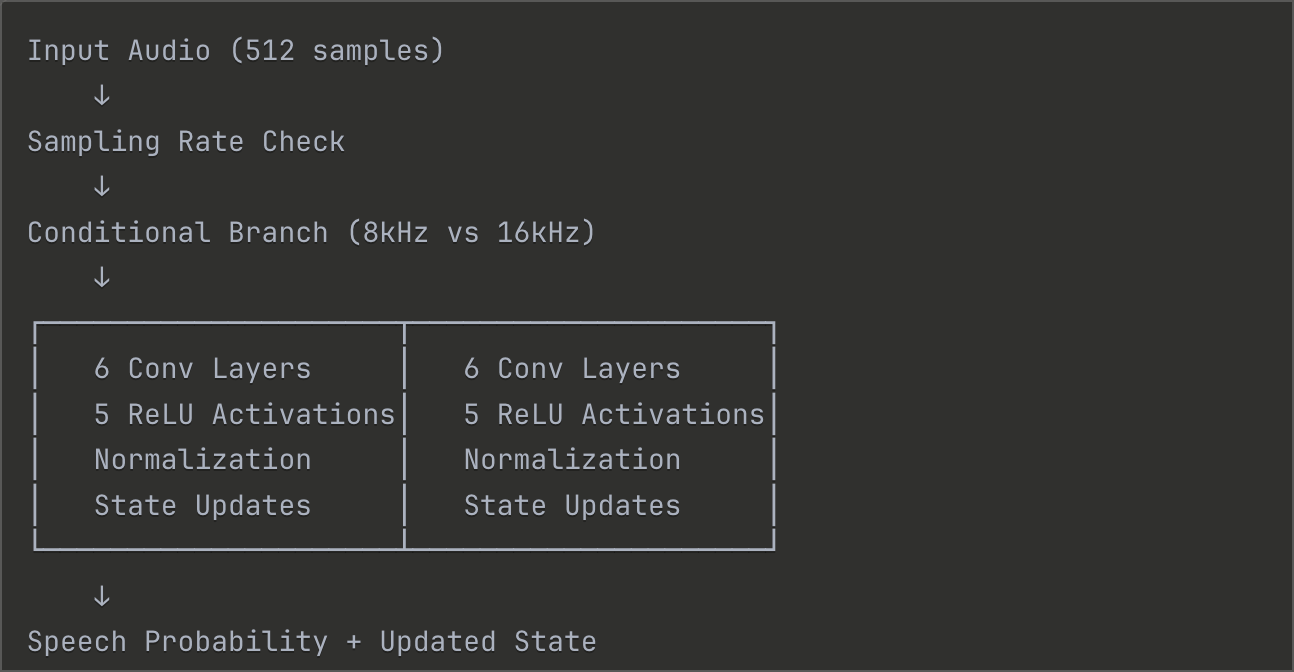
The agent then tries to understand the model and researches how to optimize it based on the user’s requirements. After about 10 minutes of analysis, our prototype mapped out the model’s execution flow and chose 16kHz, matching our existing Parakeet TDT v3 Core ML model for transcription.
The tricky part with Silero VAD is that it’s already in JIT format, pre-traced and heavily optimized for mobile and libtorch execution, making it harder to convert. JIT models are prepackaged versions of AI models made to run faster and more reliably, especially outside a developer’s laptop, but they lose the granular details of the original model.
The ONNX path failed after 30 minutes when the agent hit the IF operation, which isn’t supported in Core ML. Since ONNX has been deprecated from Core ML Tools, it abandoned this approach after trying various version permutations.
Here’s where our prototype showed promise. After finding the convert-gguf.pyscript from whisper.cpp, it realized it could rebuild the nn.Module classes from scratch using PyTorch with the provided weights instead. It loaded the weights and created separate Short-Time Fourier Transform (STFT), Encoder, and Decoder models, traced them individually, then verified each component matched the baseline. This was a strategy our manual attempt never considered.
Finding and fixing three critical bugs
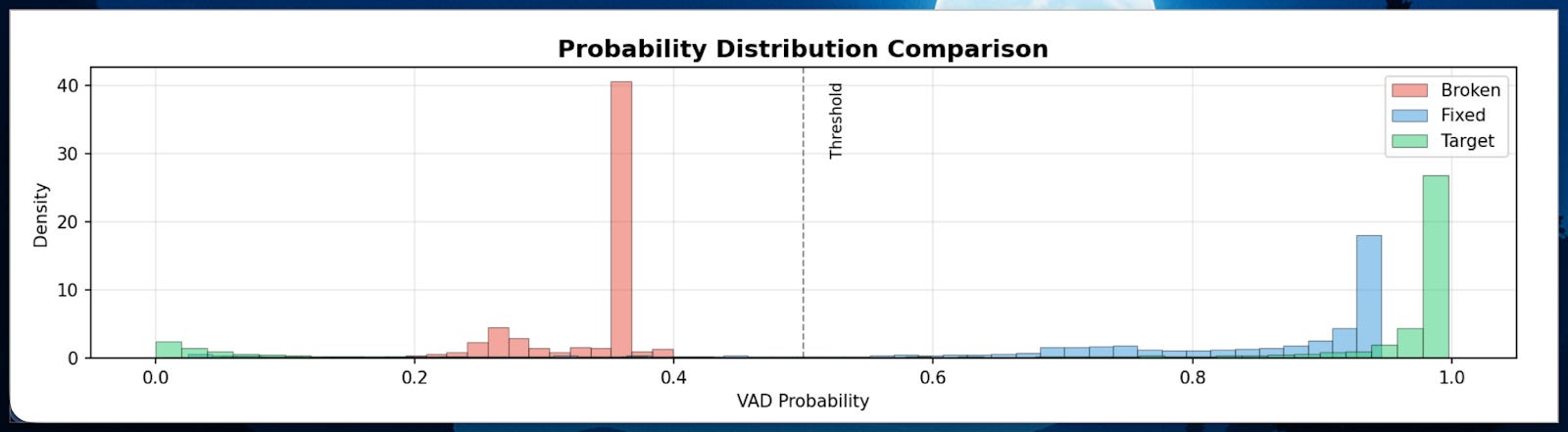
Initial conversion looked successful, but when tested with real audio data, everything fell apart. The differences compared to the baseline model were quite significant. For a VAD model, a difference of up to 30% is unusable.
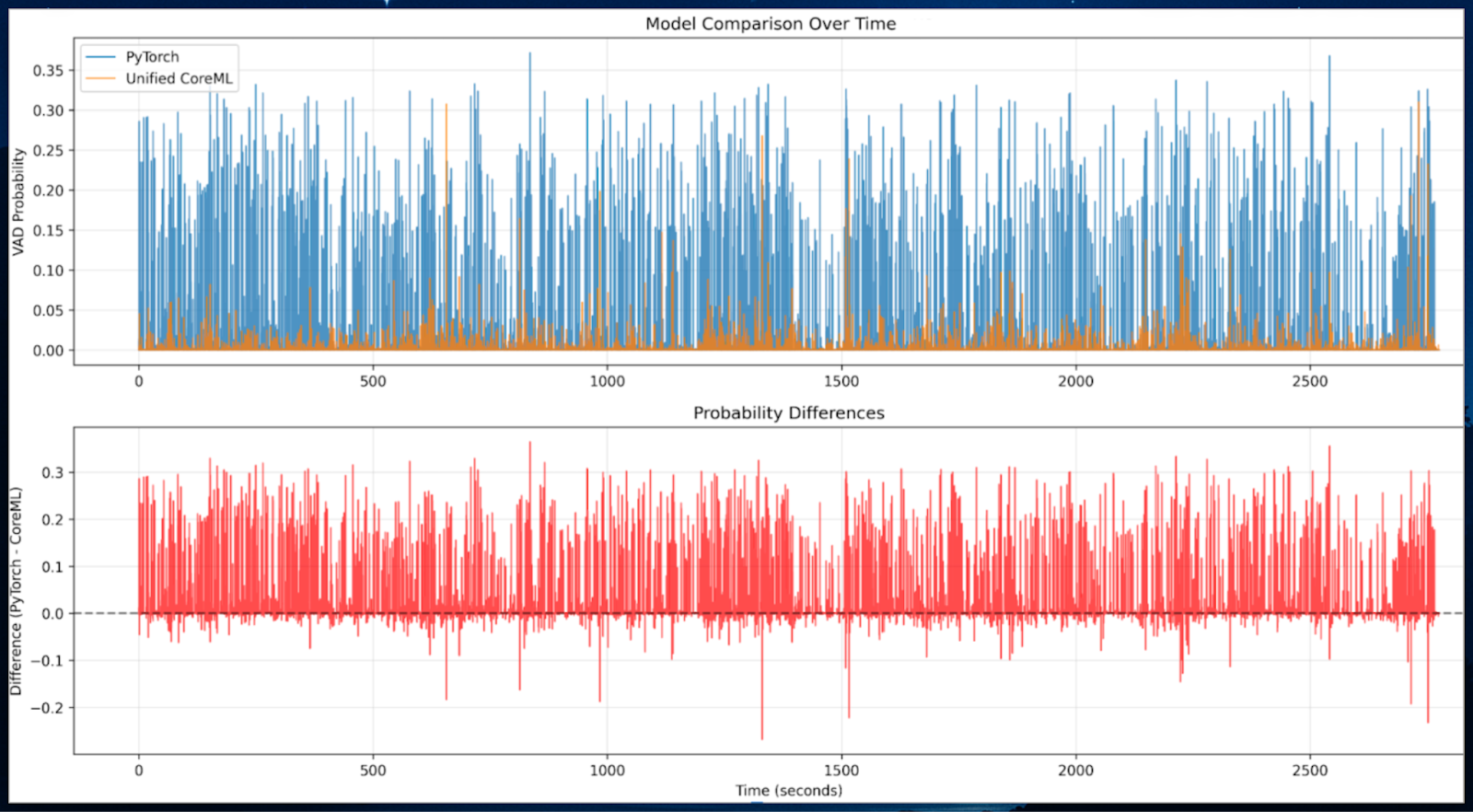
After prompting our agent to review its work, we discovered it had been comparing against the simplified baseline, not the actual PyTorch JIT model. This is a common problem with coding agents. Once corrected, the agent systematically identified three root causes that compounded into complete failure.
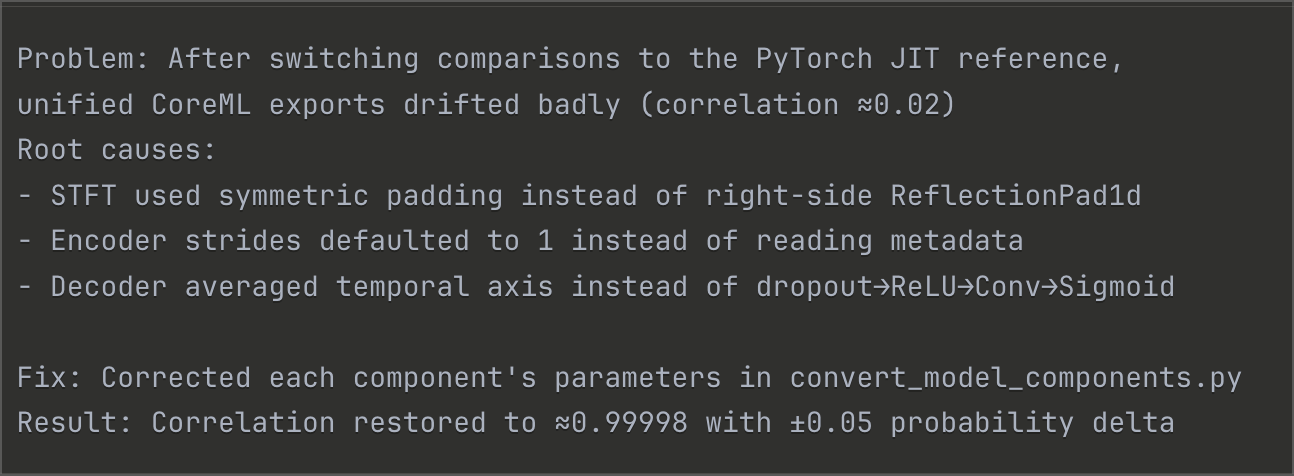
This level of systematic debugging demonstrates the potential value of AI-assisted model porting. Our manual attempt + ChatGPT/Claude had tried band-aid solutions like Squeeze-and-Excitation modifications without identifying these fundamental issues. Working with an agent with the right context and tooling helped us understand the real problems rather than applying surface-level fixes.
Speeding up with 256ms windows
With correctness achieved, our prototype focused on speed. The initial Core ML model wasn’t showing significant improvements over PyTorch JIT, defeating one purpose of conversion.
Here’s where the agent helped make a crucial discovery our team missed initially. Processing 256ms windows instead of 32ms chunks provided dramatic speedups. This isn’t traditional batching where you process multiple independent samples in parallel. It’s simply passing longer audio windows to the model in a single call.
The speedup comes from Core ML’s ahead-of-time graph optimizations, FP16 execution with BNNS and Accelerate, and a single-call unified graph that avoids per-window dispatch overhead. This results in better cache utilization and optimized memory patterns.
For combining the eight probability outputs from the 256ms window, the agent chose noisy-OR over mean or max by treating each 32ms slice as an independent expert vote. Noisy-OR better models whether voice existed in the last 256ms. It avoids overreacting to spurious spikes unlike max while preserving sensitivity to brief speech unlike mean. This optimization strategy, enabled by the unified graph execution in Core ML, led to a 3.5× improvement in inference speed.
Why this model runs faster on CPU than ANE
The agent also tried quantization and palettization by reducing the model from float32 to float16 or int8. For most large language models, quantizing provides significant speedups, but that’s generally untrue for Core ML models. For Silero VAD at around 2MB, memory isn’t the bottleneck, and the overhead of dequantization exceeds any savings for a model this size.
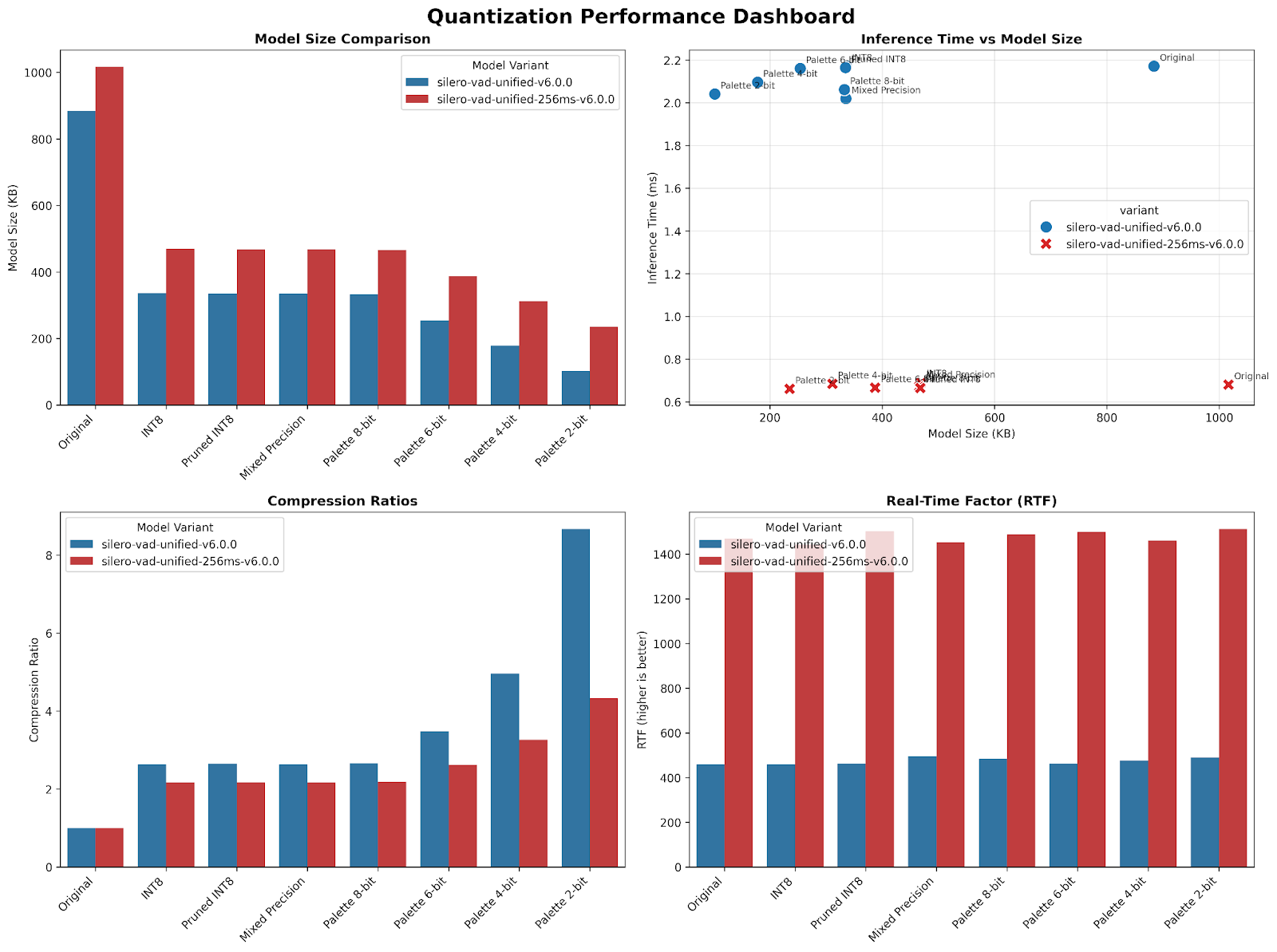
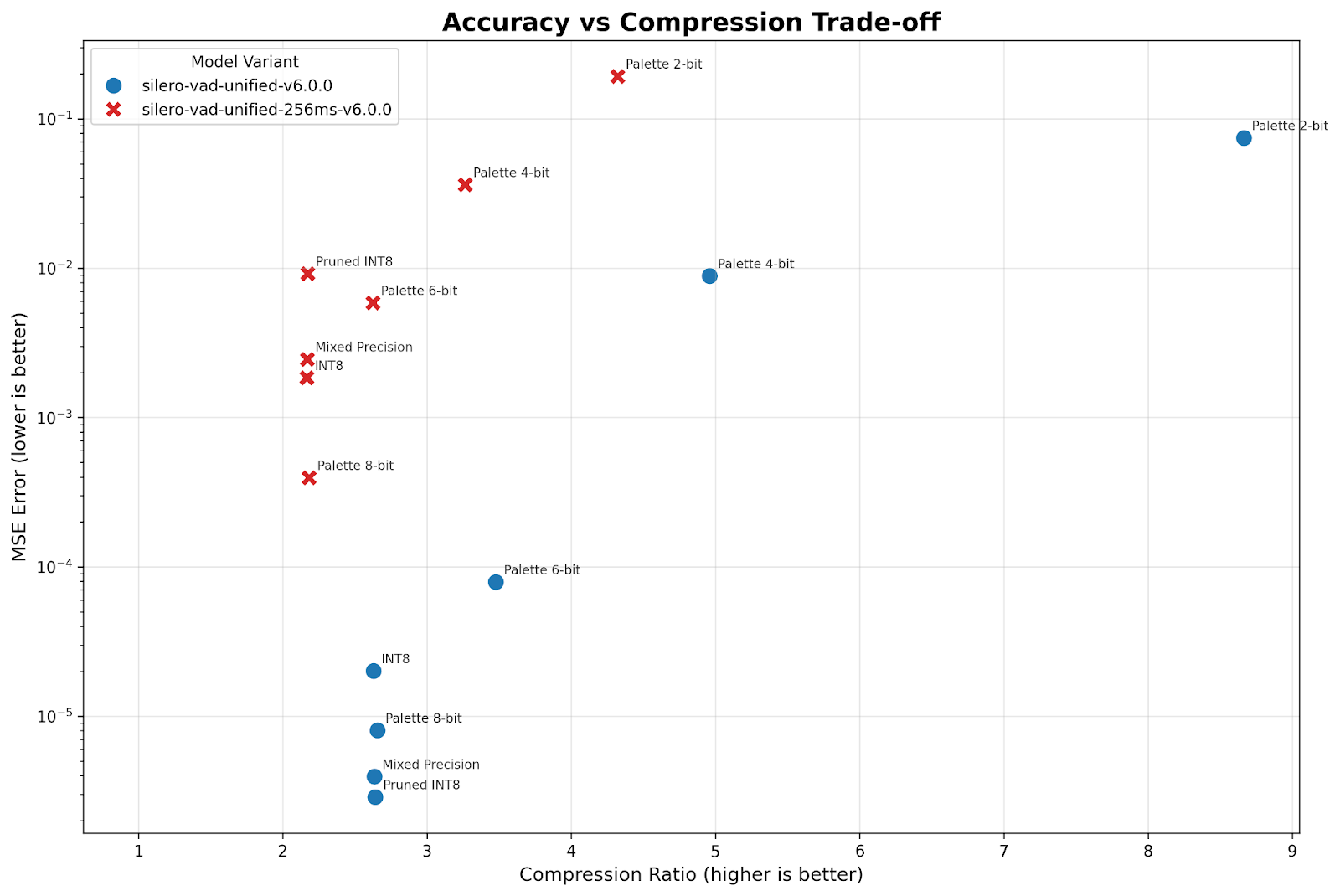
Like any optimization techniques, there’s always a sacrifice to accuracy, and it depends on the architecture of the model. These trade-offs become especially apparent when comparing model size against latency and accuracy against compression rates.
Note that there are other techniques like pruning that the agent didn’t try. This is something we need to look more into.
When we profiled the mlpackage using Xcode, the results were unexpected. The Core ML model ran 100% on CPU. We confirmed this by comparing latency between CPU-only and CPU+NE settings, which showed almost identical performance, with < 0.05ms difference.
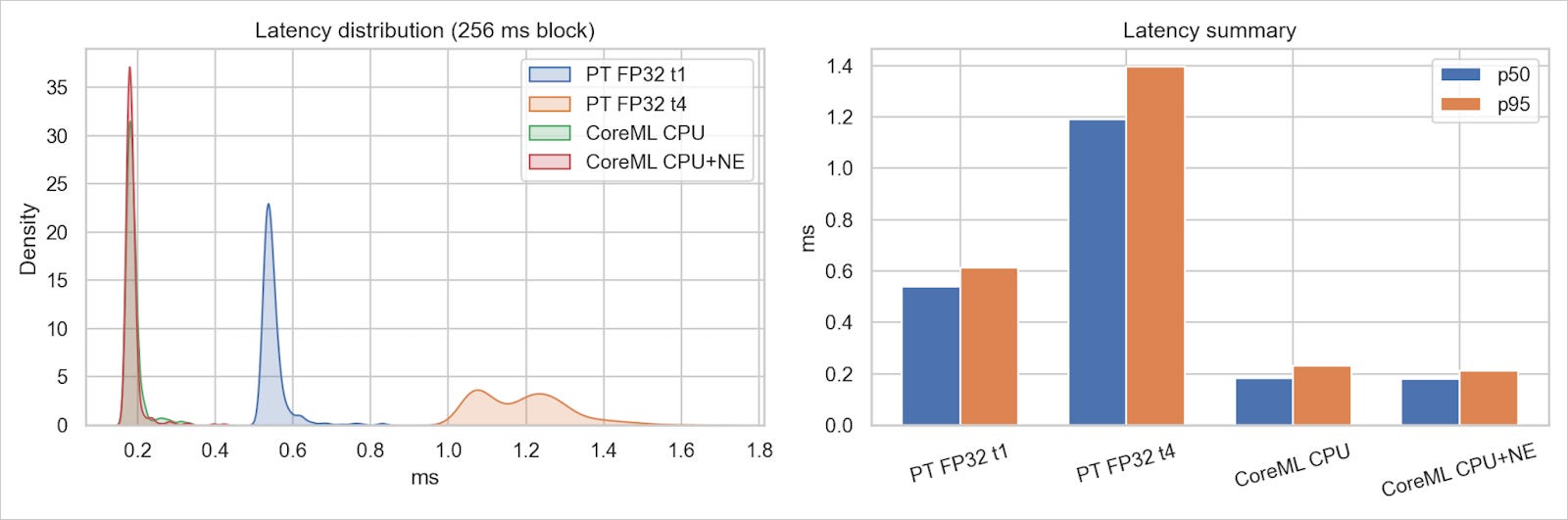
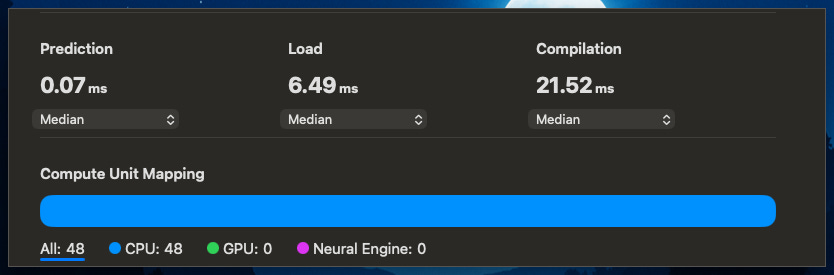
This surprised us, as we had expected some operations to run on the ANE. The profiling revealed that while the operations could technically be supported by both GPU and ANE, Core ML’s execution engine determined that CPU-only execution was optimal.
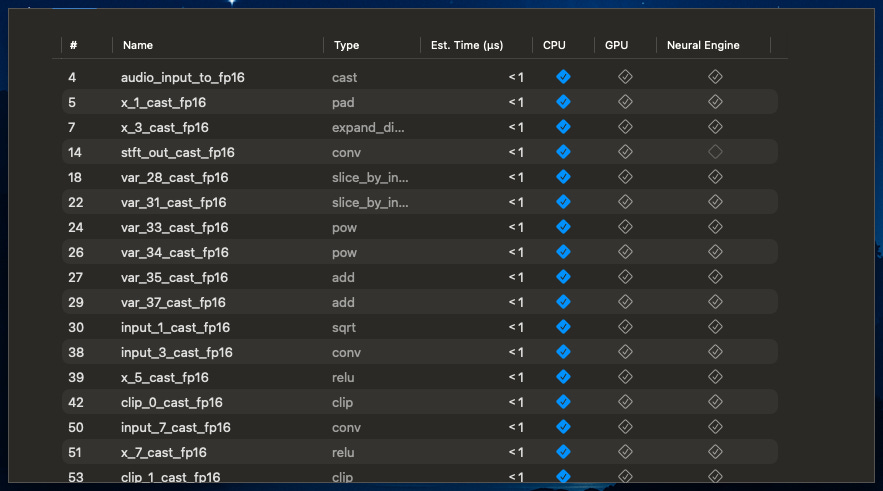
The reason likely comes down to model size. At just 2MB, the overhead of transferring data to the ANE would exceed any computational benefits. Operations like STFT and custom convolutions are simply more efficient on CPU at this scale. Unfortunately, Apple provides limited documentation on Core ML’s internal decision-making, so this analysis is based on our best understanding of the framework’s behavior.
From two weeks to twelve hours
Despite running entirely on CPU, converting to the native runtime format still unlocked significant performance optimizations. The results speak for themselves.
Using our Möbius prototype, development time dropped from two weeks to 12 hours, a 93% reduction. The human developer still made key decisions and verified results, but the AI agent handled the heavy lifting of debugging, testing variations, and systematically exploring optimizations. Accuracy remained near-perfect with 0.99998 correlation, compared to the broken manual attempt that suffered from ±0.15 to 0.2 drift on a 60-minute video with multiple speakers and varying volume. Most importantly, we achieved a 3.5× speedup versus no improvement in the manual conversion.
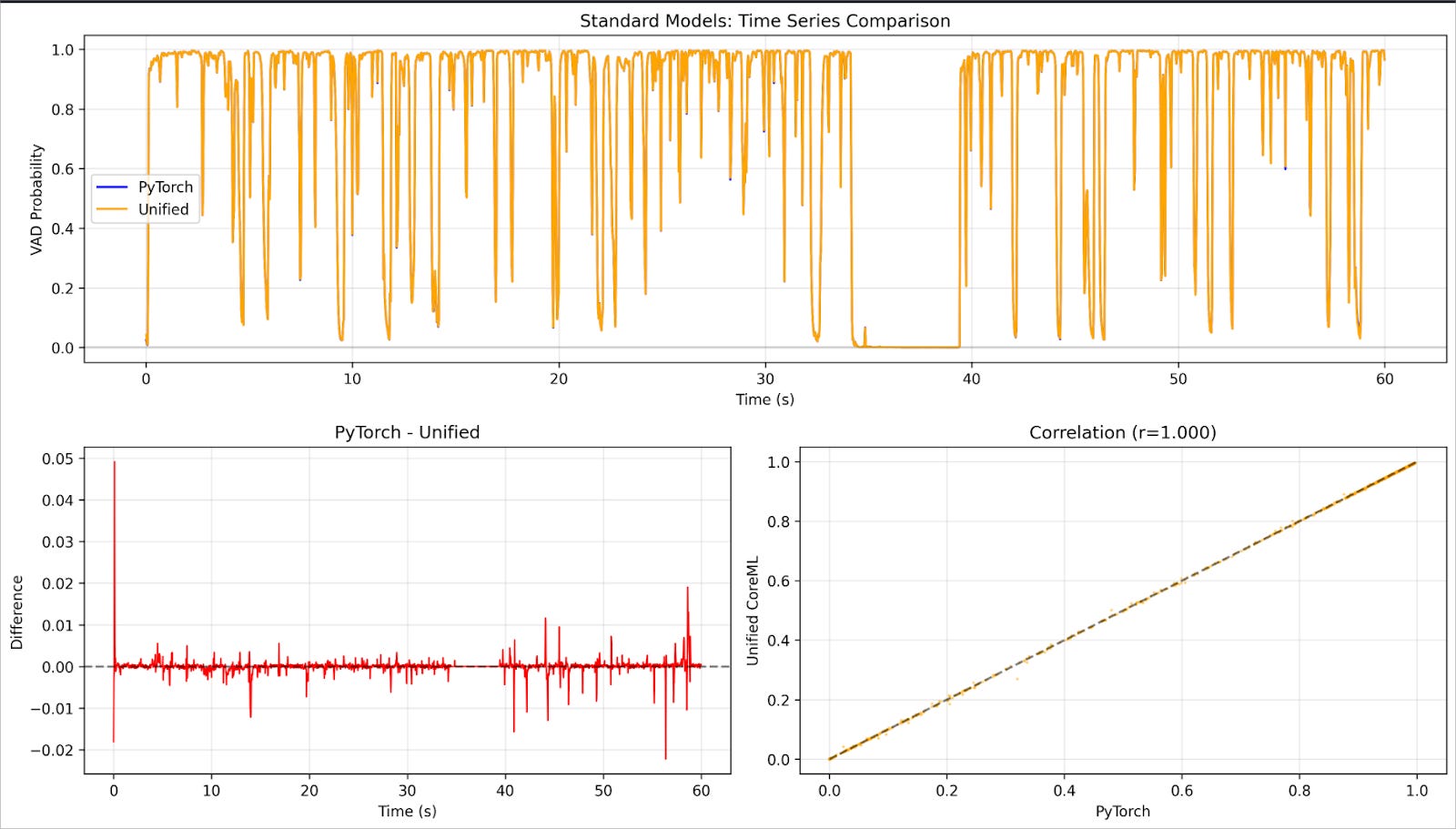
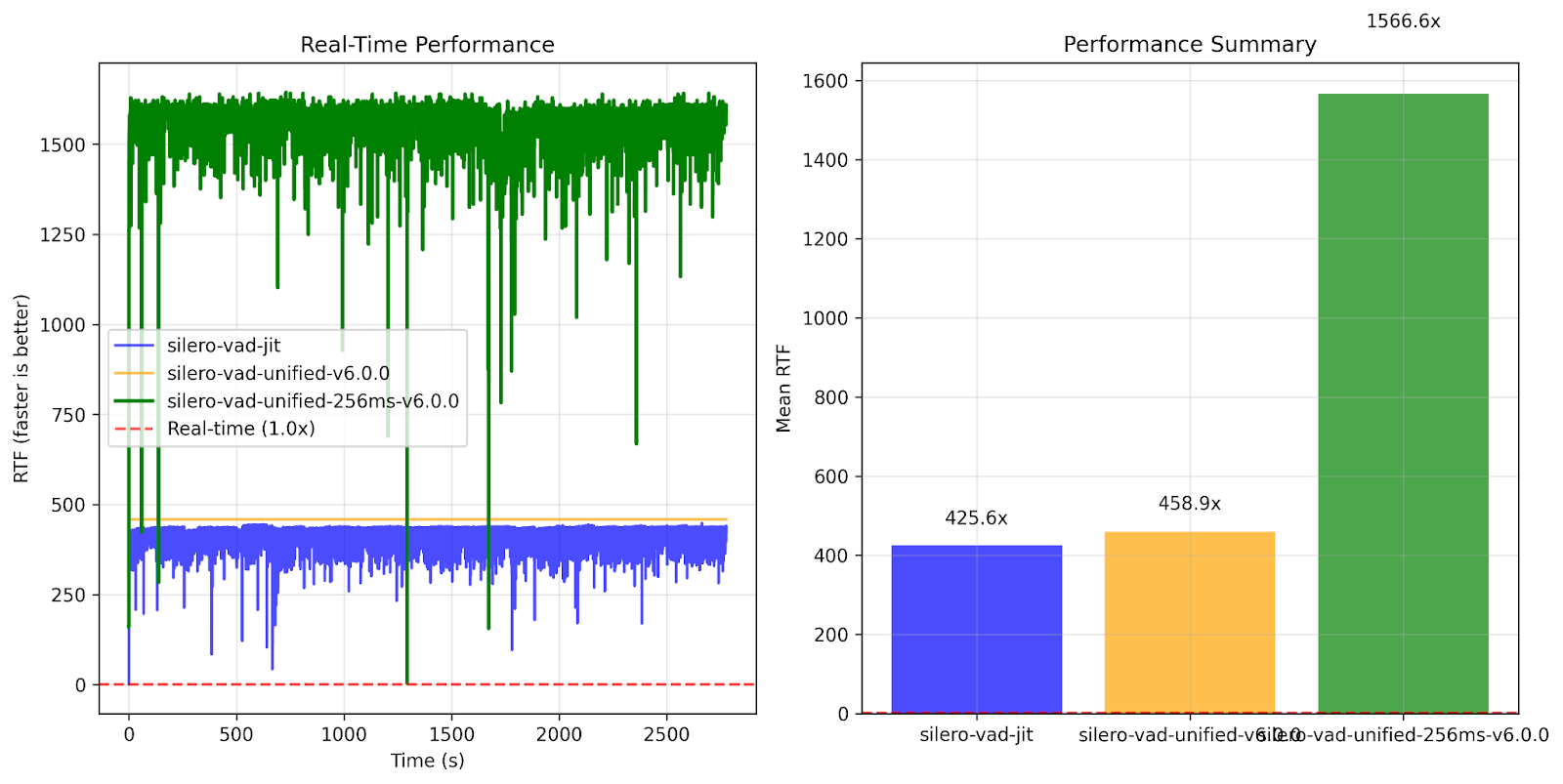
What makes this promising for our development is that the agent didn’t just speed up human work. Working together, the human-AI team discovered optimizations we missed in our manual attempt. The 256ms window processing with noisy-OR aggregation wasn’t in our manual playbook. The agent systematically explored the solution space, verified each step, and found a better path.
For use cases requiring near 32ms processing, this approach isn’t feasible, but our tests demonstrate that the 32ms Core ML model runs at 33 RTFx, approximately 8% faster than the baseline PyTorch model with much less performance jitter.
What this means for edge AI
While our prototype excels at converting simpler models like VAD, more complex architectures present challenges we’re still working to solve. Models with dynamic shapes like Kokoro still require significant human intervention. We believe these challenges can be addressed as we continue developing Möbius, and we’re actively working to extend its capabilities to handle these more complex cases while exploring how it can rewrite certain operations to better utilize the ANE.
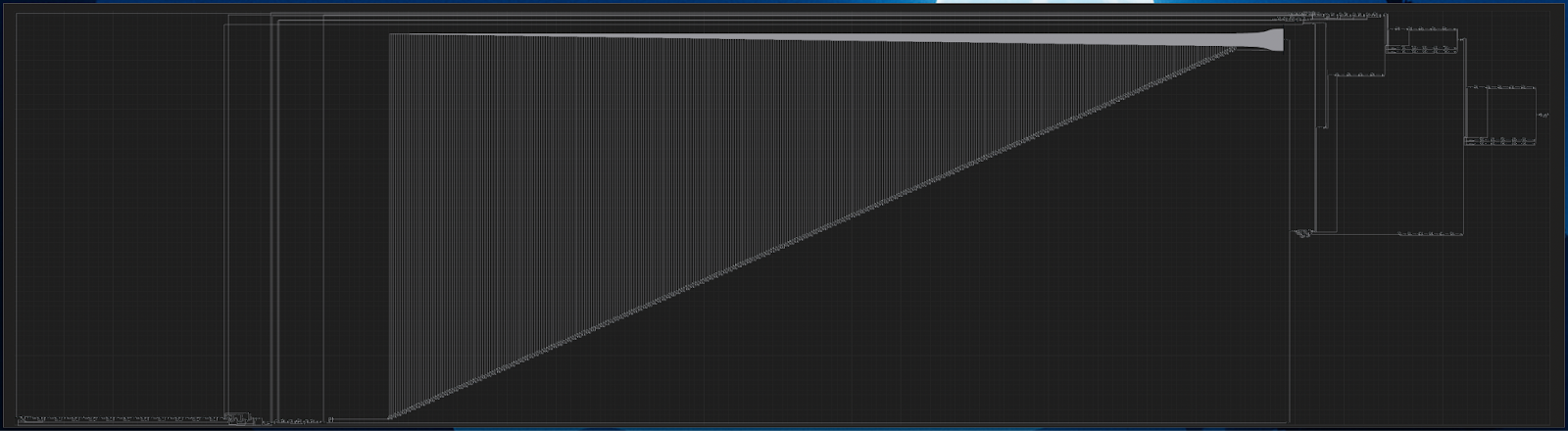
To understand the complexity gap, consider that Kokoro contains over 2,000 operations compared to Silero VAD’s 48 operations. The model structure visualizations from Xcode clearly illustrate this dramatic difference in architectural complexity.
Native restrictions also limit certain workloads on AI accelerators like ANE and NPU. For LLMs, context windows are often restricted to under 5,000 tokens, and memory bandwidth becomes the primary bottleneck. Currently, Apple’s MLX framework or llama.cpp remain better solutions for local LLM inference on Apple devices.
Each successful conversion adds to our knowledge base. We’re already seeing community contributions like CAM++ achieving 3× speedups after successfully converting the model to Core ML format.
This time around, we learned how to better handle PyTorch JIT models when the original PyTorch model isn’t available, working directly with the weights instead. While the VAD model itself is too small for meaningful ANE usage, converting to the native runtime still provides more flexibility for optimization. Eventually Möbius may even be able to redesign models to run entirely on the neural engine.
Bringing edge intelligence everywhere
Getting models to run well on edge devices is crucial for AI’s future. Devices have limited resources, requiring maximum performance optimization. While unified runtimes offer portability, they often lack the performance and efficiency of native runtimes. Yet there aren’t enough people with the deep expertise needed for this optimization work.
Native runtimes matter significantly, even on CPU. These runtimes are often optimized by the hardware maker and offer more flexibility for optimizing models. For ambient workloads on the edge, any performance optimization is critical. The challenge of model conversion requires deep understanding of multiple frameworks and debugging subtle numerical differences. However, properly structured agents with domain knowledge can handle this complexity effectively, offering a path forward through AI-assisted development that works.
This case study demonstrates the potential for AI-assisted model conversion. While we’ve successfully tested our approach on several models beyond Silero VAD, we recognize this is early work with much more to explore. The same approach that achieved 3.5× speedup for VAD extends naturally to emerging edge scenarios like fleet management systems running vision models on heterogeneous vehicle hardware, ambient monitoring with multimodal models on battery-powered sensors, and real-time data collection on industrial IoT devices.
As powerful multimodal models like Moondream3 and VoxCPM-0.5B emerge, the gap between cloud capabilities and edge constraints continues to widen, making systematic optimization increasingly vital. Each successful conversion teaches our system new patterns. What works for a 2MB VAD on Core ML informs how we’ll optimize tomorrow’s foundation models for tomorrow’s edge accelerators.
The real bottleneck in edge AI deployment isn’t the models or the hardware. It’s the expertise gap in optimization. We’re building Möbius to help bridge this gap, creating an AI coding assistant that will make sophisticated model optimization accessible to more developers. Just as GitHub Copilot changed how developers write code, we believe tools like Möbius can change how we optimize models for edge deployment, gradually dissolving the boundaries between machine learning engineers and software engineers.
At FluidInference, Möbius represents our commitment to making edge AI optimization accessible through AI-assisted development. We’re building it to be like Claude Code or Codex for model porting, specializing in the complex task of bringing models to edge devices. We’ll be sharing more details as development continues and plan to eventually open source the platform. Join our Discord to be the first to hear about it. If you’re working on edge AI or model optimization, we’d love to connect at hello@fluidinference.com.
Use the new VAD model: https://github.com/FluidInference/FluidAudio
Access möbius’s models and conversion code: github.com/FluidInference/möbius
Join our community: https://discord.gg/WNsvaCtmDe